简单绘图语言解释器(编译原理大作业)
写于:2025-01-13 改于:2025-01-13
字数:5873 阅读需要32 mins
0 前言
0.1 简述
编译原理课程要求完成一个简单的绘图语言解释器,笔者准备完成一个基于Python及其flask框架的解释器,顺便复习知识点以及完善编译原理笔记。项目见这里
0.2 要求
为函数绘图语言编写一个解释器,输入为用函数绘图语言编写的源程序
- 用词法分析器识别其中的记号(可将记号的信息显示出来);
- 用语法分析器识别记号流中的语句(可将语句结构显示出来);
- 解释器:词法分析、语法分析、语义分析/计算,绘制图形。
0.3 函数绘图语言
举例:
-------------------------- 函数f(t)=t的图形
origin is (100, 300); -- 设置原点的偏移量
rot is 0; -- 设置旋转角度(不旋转)
scale is (1, 1); -- 设置横坐标和纵坐标的比例
for T from 0 to 200 step 1 draw (t, 0);
-- 横坐标的轨迹(纵坐标为0)
for T from 0 to 150 step 1 draw (0, -t);
-- 纵坐标的轨迹(横坐标为0)
for T from 0 to 120 step 1 draw (t, -t);
-- 函数f(t)=t的轨迹
语句满足下述规定(原则):
- 各类语句可以按任意次序书写,且非注释语句以分号结尾。解释器按照语句出现的先后顺序处理。
ORIGIN、ROT和SCALE语句只影响其后的绘图语句,且遵循最后出现的语句有效的原则。 例如,若有下述ROT语句序列:ROT IS 0.7 ; ... ROT IS 1.57 ; ...则随后的绘图语句将按1.57而不是0.7弧度旋转。
- 无论
ORIGIN、ROT和SCALE语句的出现顺序如何,图形的变换顺序总是:比例变换–>旋转变换–>平移变换 - 语言对大小写不敏感,例如
for、For、FOR等,均被认为是同一个保留字。 (处理时将所有字母大写) - 语句中表达式的值均为双精度类型,旋转角度单位为弧度且为逆时针旋转,平移单位为像素点。
0.4 引言
我完成了一个基于Python及Flask框架的解释器,主要参考了这个博客以及对应的github项目,我的主要工作包括仔细阅读并修改部分代码;将文件流修改为字符串流便于前端界面读取使用;统一了词法、语法分析器的日志输出;修复了两个bug(见该issue);添加了Color声明语句;创建前端页面内容;简化了一些函数逻辑。
0.5 环境配置
软件环境:
Microsoft Windows 11 家庭中文版 版本:10.0.22631
Python 3.12.4
matplotlib 3.8.4
Flask 3.0.3
如果没有安装Flask框架,可以运行pip install Flask进行安装
硬件环境:
CPU: 12th Gen Intel(R) Core(TM) i7-12700H 2.70 GHz
GPU: NVIDIA GeForce RTX 3070Ti Laaptop GPU
1 词法分析器(scanner)
词法分析器确定输入的每个记号的正确与否,包括常数、参数、函数、保留字、运算符、分隔符。
词法分析器需要将标记记号的种类,供语法分析器使用;去除无用部分如空格,回车等;发生错误时报错。
1.1 Token类(Token.py)
Token类负责初始化并保存每个记号的相关数据。 ppt提供的数据结构:
struct Token
{ enum Token_Type type; // 类别,见下页
char * lexeme; // 属性,原始输入的字符串,亦可为数组
double value; // 属性,若记号是常数则存常数的值
double (* FuncPtr)(double); // 属性,若记号是函数则存函数地址
// … 按需增加其他成员 …
};
enum Token_Type // 记号的类别
{
ID, COMMENT, // 参见正规式设计
ORIGIN, SCALE, ROT, IS, // 保留字(一字一码)
TO, STEP, DRAW,FOR, FROM, // 保留字
T, // 参数
SEMICO, L_BRACKET, R_BRACKET, COMMA,// 分隔符
PLUS, MINUS, MUL, DIV, POWER, // 运算符
FUNC, // 函数(调用)
CONST_ID, // 常数
NONTOKEN, // 空记号(源程序结束)
ERRTOKEN // 出错记号(非法输入)
};
struct Token TokenTab[] =
{
//常数,常函数,常量定义
};
修改后的python语句见代码,其中添加的color类型声明记号见这里。
1.2 Scanner类(Scanner.py)
Scanner类负责将符号保存到Token类中并处理异常情况。
课程示例中该类的输入为文件名,笔者想要基于Flask框架完成一个界面来展示,该处输入应该为代码的字符串。为方便编写,笔者查询到了StringIO类,该类允许用户将String类看作一个文件进行读写操作。
具体代码见项目文件,此处笔者根据参照内容将多个函数简化为判断语句。
2 语法分析器(parser)
语法分析器的主要工作如下:
- 设计函数绘图语言的文法,使其适合递归下降分析;
- 设计语法树的结构,用于存放表达式的语法树;
- 设计递归下降子程序,分析句子并构造表达式的语法树;
- 设计测试程序和测试用例,检验分析器是否正确。
在ppt中提供了使用文法的具体推导过程,在此不做记录。
最终文法如下:
Program --> { Statement SEMICO }
Statement --> OriginStatment | ScaleStatment
| RotStatment | ForStatment
OriginStatment --> ORIGIN IS
L_BRACKET Expression COMMA Expression R_BRACKET
ScaleStatment --> SCALE IS
L_BRACKET Expression COMMA Expression R_BRACKET
RotStatment --> ROT IS Expression
Expression --> Term { ( PLUS | MINUS ) Term }
Term --> Factor { ( MUL | DIV ) Factor }
Factor --> ( PLUS | MINUS ) Factor | Component
Component --> Atom [ POWER Component ]
Atom --> CONST_ID
| T
| FUNC L_BRACKET Expression R_BRACKET
| L_BRACKET Expression R_BRACKET
由于这是一个EBNF格式,笔者并未找到课程内的相关解释(后来找到了,教材与复习资料中均存在解释),此处记录相关符号如下:
| 记号 | 意义 |
|---|---|
| = | 定义(此处被替换为–>) |
| , | 连接符(此处被忽略) |
| ;(SEMICO) | 结束符 |
| | | 或 |
| […] | 可选 |
| {…} | 重复 |
| (…) | 分组 |
| “…” | 终端字符串 |
| ‘…’ | 终端字符串 |
| (…) | 注释 |
| ?…? | 特殊数列 |
| - | 除外 |
2.1 ExprNode类(Parser_node.py)
ExprNode类定义了一个节点类,供Parser类实现语法树时进行调用。
在此类中我简化了符号的判断,添加了一个符号表OperatorTokenType用以简化冗长的判断语句。
GetValue()供Parser类提取规约时语法树节点的值。
2.2 Parser类(Parser_process.py)
Parser类是语法分析器的主体,实现了上文提到的语法树的判断。
FetchToken()通过Scanner类获取下一个Token,通过文法的非终结符构建的函数组成的调用链以及对类内数值赋值实现了文法。例如在我添加的两句文法中,如果在Statment后捕捉到“COLOR”关键字就调用ColorStatement()函数,在捕捉到“COLOR IS”后调用ColorExpression()函数判断颜色表达式,如果下一个token是颜色常量将颜色赋值到self.color中,如果不是判断是否为三元数组,复制给self.color。
3 语义分析器(semantic)
Semantic类是Parser的子类,主要的修改在于重载了Statment()函数,在ForStatment()函数后添加了Draw()函数将当前点数据绘制到图像中。
calc()函数计算了在旋转,平移,拉伸后的点数据,而由于python自带的sin与cos函数不支持以数组形式进行运算故在此使用numpy库中的函数(见词法分析引入函数)。
4 各测试类(tester)
在完成每一个部分后需要对该部分进行测试,故编写了词法与语法的测试类(Scanner_tester.py && Parser_tseter.py),同时通过flask框架将以上内容集成到输出内容中便于调试。
参考内容通过单独文件进行测试,而笔者将测试内容输出集成到各分析器的主类中,编写了Getlog()函数便于后续调用。
5 主函数(Main.py && app.py)
Main.py是不集成Flask框架的程序,理论上也是一个测试类,app.py则是集成了框架并对网页输入进行反应的程序。
主要流程是先创建scanner类对输入语句进行词法分析,后将处理结果传入semantic类中进行语法分析并同时绘制结果,最后将结果保存。
scanner = Scanner(test_str2) #对测试语句词法分析
print(scanner.GetLog()) #输出日志(分析结果)
semantic = Semantic(scanner) #词法分析结果传入语义分析器
semantic.init() #初始化语法,语义分析器
semantic.Parser() #语法分析
save_path = "./static/test.png" #保存路径
semantic.SaveFig(save_path) #保存图片
print(semantic.GetLog()) #输出语法分析结果
6 添加内容(原创性工作说明)
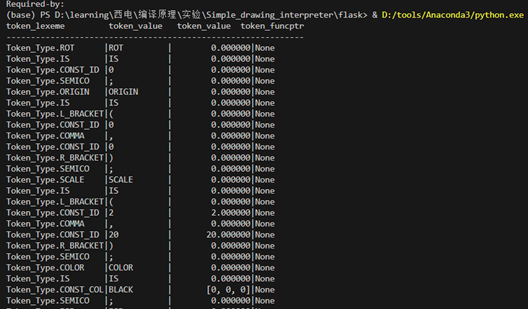
6.1 COLOR语句
尝试添加Color声明 先看看color的语句例子:
color is (255,255,0);
首先添加TOKEN:
TokenType = Enum("Token_Type", (
...
#ADD BY SKY
"COLOR", # 颜色设置
"CONST_COL" # 颜色常量
))
TokenTab = {
...
#ADD BY SKY
"COLOR": Tokens(TokenType.COLOR, "COLOR", 0.0, None),
"BLUE": Tokens(TokenType.CONST_COL, "BLUE", [0,0,255], None),
"GREEN": Tokens(TokenType.CONST_COL, "GREEN", [0,255,0], None),
"RED": Tokens(TokenType.CONST_COL, "RED", [255,0,0], None),
"BLACK": Tokens(TokenType.CONST_COL, "BLACK", [0,0,0], None),
"WHITE": Tokens(TokenType.CONST_COL, "WHITE", [255,255,255], None)
}
然后在Scanner_tester中测试:
token_lexeme token_value token_value token_funcptr
------------------------------------------------------------
Token_Type.COLOR |COLOR | 0.000000|None
Token_Type.IS |IS | 0.000000|None
Token_Type.L_BRACKET|( | 0.000000|None
Token_Type.CONST_ID |255 | 255.000000|None
Token_Type.COMMA |, | 0.000000|None
Token_Type.CONST_ID |255 | 255.000000|None
Token_Type.COMMA |, | 0.000000|None
Token_Type.CONST_ID |0 | 0.000000|None
Token_Type.R_BRACKET|) | 0.000000|None
Token_Type.SEMICO |; | 0.000000|None
Token_Type.NONTOKEN | | 0.000000|None
可以正常读取。
为了添加color声明语句,需要修改原先的状态转移图:
Program --> { Statement SEMICO }
Statement --> OriginStatment | ScaleStatment
| RotStatment | ForStatment | ColorStatment
...
ColorStatment --> COLOR IS
L_BRACKET Expression COMMA Expression COMMA Expression R_BRACKET
...
故需要在Parser_process以及Semantic中修改函数Statment(),添加ColorStatement()声明语句以及相关变量:
class Parser(object):
def __init__(self,scanner):
...
self.color = [0,0,0]
...
def Statement(self): # 为每一个语句转进每一种文法
self.enter("Statement")
if self.token.type == TokenType.ORIGIN:
...
# ADD BY SKY
elif self.token.type == TokenType.COLOR:
self.ColorStatement()
...
self.back("Statement")
...
def ColorStatement(self): # color声明语句
self.enter("ColorStatement")
self.MatchToken(TokenType.COLOR)
self.call_match("COLOR")
self.MatchToken(TokenType.IS)
self.call_match("IS")
self.MatchToken(TokenType.L_BRACKET)
self.call_match("(")
temp = self.Expression()
self.color[0] = temp.GetValue()
self.MatchToken(TokenType.COMMA)
self.call_match(",")
temp = self.Expression()
self.color[1] = temp.GetValue()
self.MatchToken(TokenType.COMMA)
self.call_match(",")
temp = self.Expression()
self.color[2] = temp.GetValue()
self.MatchToken(TokenType.R_BRACKET)
self.call_match(")")
self.back("ColorStatement")
再修改Semantic中的Draw()函数
def Draw(self):
x, y = self.calc(self.x_ptr, self.y_ptr)
color_normalized = [(c % 256) / 255 for c in self.color]
self.ax.scatter(x, y, color=color_normalized)
为了确保正常运行,此处将颜色常量对256取余后作除法,处理不在[0,255]的常量,并假设颜色输入均为整数表示。
颜色常量
还存在BLUE表示蓝色等常量,但该常量与PI等常量不同的是该常量是包含3个值的数组,修改的内容较多。
文法如下:
Program --> { Statement SEMICO }
Statement --> OriginStatment | ScaleStatment
| RotStatment | ForStatment | ColorStatment
...
ColorStatment --> COLOR IS ColorExpression
ColorExpression --> L_BRACKET Expression COMMA Expression COMMA Expression R_BRACKET
--> CONST_COL
...
对于Scanner,扫描时token.value的输出log函数需要修改,如果是元组需要将输出修改为字符串,而且由于原value字段长度最长为12,而最长的颜色白色[255 ,255 ,255]有15个字符,故将value字段扩展到16位。
def LogToken(self,token,width_value=16):
if isinstance(token.value, tuple): # 如果是元组,转成字符串
value_str = str(token.value).rjust(width_value)
elif isinstance(token.value, (int, float)): # 如果是数值,格式化为浮点数
value_str = "{:16f}".format(token.value)
else: # 其他类型直接转字符串
value_str = str(token.value).rjust(width_value)
# 使用格式化后的值输出日志
self.log("{:20s}|{:12s}|{:16s}|{}".format(
token.type, # 类型
token.lexeme, # 词素
value_str, # 处理后的值
token.funcptr # 函数指针
))
在Parser中token.value的log函数同样需要修改。
def PrintTree(self,root,indent):
...
# 适配颜色常量
elif root.item == TokenType.CONST_ID:
if isinstance(root.value, (int, float)): # 如果是整数或浮点数
self.log(f"{root.value:.5f}") # 保留 5 位小数
elif isinstance(root.value, tuple): # 如果是元组
self.log(f"({', '.join(f'{v:.5f}' if isinstance(v, (int, float)) else str(v) for v in root.value)})")
else: # 其他类型
self.log(str(root.value))
...
Parser的测试结果正常:
...
Enter Statement
Enter ColorStatement
Match Token COLOR
Match Token IS
Enter Expression
[0, 0, 255]
Leave Expression
Leave ColorStatement
Leave Statement
Match Token ;
...
6.2 bugfix
绘制时旋转语句表现错误
在绘制旋转的爱心曲线时没有正常绘制:
rot is -pi/2;
origin is (0, 0);
color is (255,0,0);
for t from -pi to pi step pi/200 draw((2*cos(t) - cos(2*t)), (2*sin(t)-sin(2*t)) );
而词法,语法分析器日志均没有报错。
在仔细检查代码后发现Semantic类中的calc()函数中的旋转代码出现错误,对y的旋转赋值语句应该为y = y * np.cos(self.rot) - x * np.sin(self.rot),而源代码为y *= np.cos(self.rot) - x * np.sin(self.rot),可能是在修改代码时想将y = y * ...优化为y =* y ...但忽略了之后的减运算部分。
修改的方式:将y =* y ...还原为y = y * ...
修改中遇到的问题及解决方案:bug定位较为繁琐,而当词法,语法分析器日志均没有报错,而输出与预期不符时,我认为问题出在绘制的问题上,在检查Semantic类后发现calc()函数的错误,但在修复后又发现了以下bug。
绘制时原点出现错误
原点设置出现错误,且只出现在Scale声明语句之后。例如绘制这段代码的图像时:
------- 函数f(t)=t的图形
origin is (1, 100); -- 设置原点的偏移量
scale is (2, 1); -- 设置横、纵坐标缩放比例
rot is pi/2; -- 设置旋转角度
for T from 0 to 200 step 1 draw (t, 0); -- 横坐标
for T from 0 to 180 step 1 draw (0, t); -- 纵坐标
for T from 0 to 150 step 1 draw (t, t); -- f(t)=t
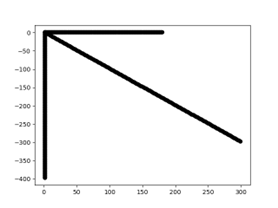
可以看到原点并不在(1,100)而是仍在原点附近。同时词法、语法分析器日志均未报错。 修改的方式:修改错误的函数。
修改中遇到的问题及解决方案:同样是词法、语法分析器日志均未报错,此时我发现该bug只出现在scale声明语句后,于是去检查了修改self.y_origin与self.x_origin的位置,发现在ScaleStatement()出现了对self.y_origin的修改,删去后代码恢复正常。
7 总结
我的解释器结合了词法分析、语法分析和语义分析,通过递归下降方法和抽象语法树(AST)的实现,直观展现从代码到功能的映射过程;采用模块化设计,各个功能模块(如词法分析、语法分析、语义分析、图形绘制等)相对独立,方便后续扩展(如增加更多绘图语言的语法功能);结合 Flask 框架,实现 Web 交互。支持用户在线提交代码并实时查看绘图结果。
解释器语法功能较为简单,仅支持基础的绘图语句(如 ROT、SCALE、FOR-DRAW 等)。对高级功能(如条件语句、变量赋值、复杂函数定义等)支持不足,难以模拟真实语言的复杂性;输入支持的语言语法不够灵活,健壮性不足,错误的代码可能直接使程序报错;Flask Web 前端功能较为基础,界面设计简陋,缺少现代化 UI 的支持。
感谢编译原理教师王老师的教学,感谢前辈BBBBchan提供的参考文档,代码文件与开源许可。